인공지능/딥러닝
딥러닝(Deep Learning) - 오버피팅(Overfitting)과 언더피팅(Underfitting)
RosyPark
2020. 6. 11. 14:24
* 오버피팅과 언더피팅이란?
* 오버피팅을 방지하기 위해서는?
(1) Weight Sharing
(2) 가중치 감소
(3) 조기종료
(4) Dropout
(5) Batch Normalization
0. Regularization(일반화 기법)
- 모델의 복잡도를 낮춰서 Test 데이터에 대한 정확도를 높인다.
- Overfitting을 방지하기 위해서
1. Regularization Term 넣기
Weight Decay
1.1 L1 Regularization
- 0에 매우 가까운 대부분의 가중치
- 가장 중요한 입력의 작은 하위 집합을 선택
- 입력 잡음에 강함
- $gamma$ : 비율 조정
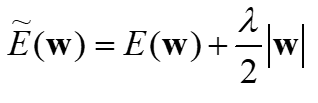
1.2 L2 Regularization
- 최고 가중치에 불이익
- 일부 입력 만 많이 사용하지 않고 모든 입력을 약간 사용하도록 권장
- L2를 L1 보다 더 많이 쓴다
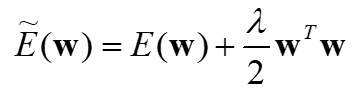
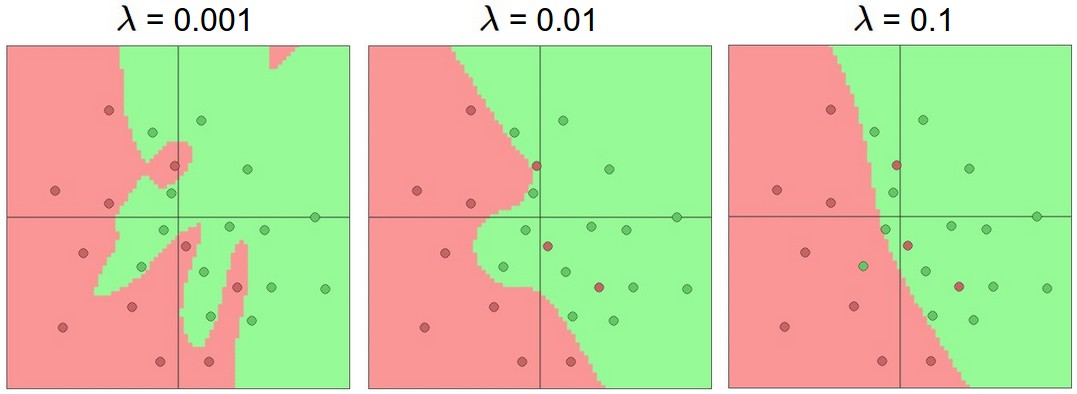
2. Dropout
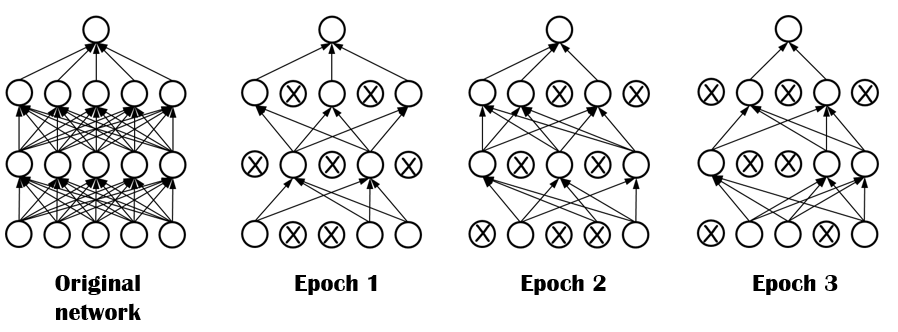
3. Data Augmentation
데이터 증대를 하여 트레이닝 데이터의 다양성과 양을 늘려 overfitting 방지한다

4. Batch Normalization
- 배치 정규화
- 배치 단위로 정규화 해주어 학습을 안정화 시키기
- Vanishing Gradient Problem이 발생하는 이유 : Internal Covariate Shift라는 Network의 각 층이나 Activation 마다 input의 distribution이 달라지는 현상 때문

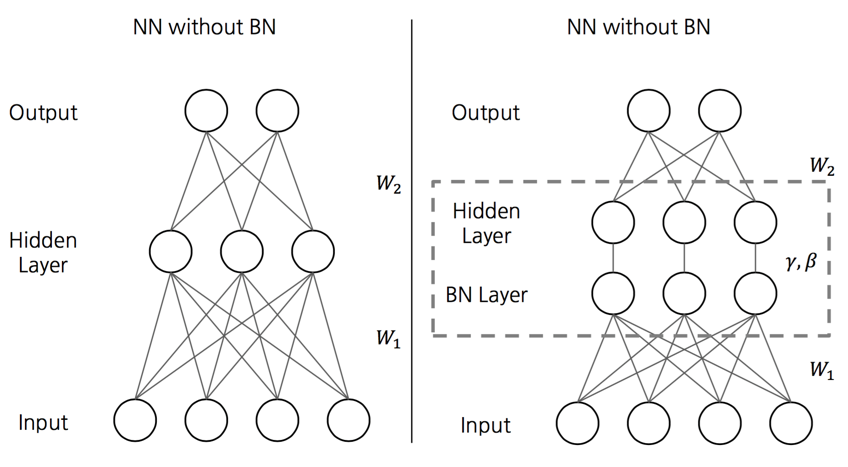

- 각 층에 활성화 함수를 통과하기 전에 모델에 연산을 하나 추가
- 단순하게 입력 데이터의 평균을 0으로 만들고 정규화한 다음, 각 층에서 두개의 새로운 파라미터로 결괏값의 스케일을 조정하고 이동시킴
- (하나는 스케일 조정을 위해, 하나는 이동을 위해 필요)
- 이 연산으로 모델이 층마다 입력 데이터의 최적 스케일과 평균을 학습
- Internal Covratiate Shift 문제를 줄이는 대표적인 방법 중 하나는 각 layer로 들어가는 입력을 whitening 시키는 것이다.
<출처>
1. http://cs231n.github.io/neural-networks-1/
2,