
티스토리 뷰
해시테이블(Hash Table)?

- 해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 인덱스 혹은 주소 삼아 데이터의 값(value)을 키와 함께 저장하여 검색을 빠르게 하기 위한 자료 구조
- 연관 배열 추상 데이터 유형을 구현하는 데이터 구조로서, 키를 값에 매핑할 수 있는 구조
- 해싱(Hashing)? 테이블을 인덱싱하기 위해 해시 함수를 사용하는것 , 정보를 가능한 한 빠르게 저장하고 검색
- 체크섬, 손실압축, 무작위화 함수, 암호 등과도 관련이 깊으며, 때로는 서로 혼용도 됨
- 성능좋은 해시 함수 특징 (1) 해시 함수 값 충돌의 최소화, (2) 쉽고 빠른 연산 (3) 해시 테이블 전체에 해시값이 균일하게 분포 (4) 사용할 키의 모든 정보를 이용하여 해싱 (5) 해시 테이블 사용 효율이 높을 것
해시테이블 충돌 처리 방법
(1) 개별체이닝 방식(Separate Chaining)

- 충돌 발생 시 그림과 같이 연결 리스트로 연결(link)하는 방식
- 충돌이 발생한 윤아와 서현은 윤아의 다음 아이템이 서현인 형태로 서로 연결 리스트로 연결
- 해시 테이블 구조의 원형이기도 하며 가장 전통적인 방식
- 흔히 해시 테이블이라고 하면 바로 이 방식을 말함
(2) 오픈 어드레싱 방식

- 충돌 발생 시 그림과 같이 탐사를 통해 빈 공간을 찾아나서는 방식
- 무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어드레싱 방식은 전체 슬롯의 개수 이상은 저장할 수 없음
- 그림은 가장 간단한 방식인 선형 탐사(Linear Probing) 방식이며 충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 하나씩 진행
- 특정 위치가 선점되어 있으면 바로 그 다음 위치를 확인하는 식이다. 이렇게 탐사를 진행하다가 비어 있는 공간을 발견하면 삽입
체이닝과 선형 탐사 방식의 로드 팩터에 따른 성능 비교
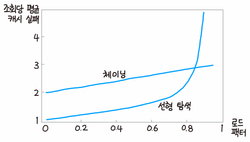
- 파이썬의 리스트와 딕셔너리는 해시 테이블로 구현됨
- 파이썬은 체이닝시 malloc으로 메모리를 할당하는 오버헤드가 높아 오픈 어드레싱 사용
- 로드팩터란?
--> 해시 테이블에 저장된 데이터개수 n 을 버킷의 개수 k개로 나눈 것
--> 로드 팩터 비율에 따라서 해시 함수를 재작성해야 될지 또는 해시 테이블의 크기를 조정해야 할지 결정
--> 이 값은 해시 함수가 키들을 잘 분산해주는지 말하는 효율성 측정에도 사용
--> 자바 10에서는 해시맵의 디폴트로드팩터 0.75, '시간과 공간 비용의 적절한 절충안'
각 언어별 해시 테이블의 구현 방식
|
언어
|
방식
|
|
C++(GCC libstdc++)
|
개별 체이닝
|
|
자바
|
개별 체이닝
|
|
고(Go)
|
개별 체이닝
|
|
루비
|
오픈 어드레싱
|
|
파이썬
|
오픈 어드레싱
|
Hash Table - LeetCode
https://leetcode.com/tag/hash-table/
Hash Table - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
3. Longest Substring Without Repeating Character
(1) collections.Counter 이용한 방법
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
graph = collections.Counter(nums)
for num in nums:
graph[num] += 1;
result = [];
for key,value in graph.most_common(k):
result.append(key)
return result(2)
key = lambda kv : kv[0] key 기준 정렬
key = lambda kv : lv[1] value 기준 정렬
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
nums = [1,1,1,2,2,3]
graph = collections.defaultdict(int)
for num in nums:
graph[num] += 1;
sorted_x = sorted(graph.items(), key = lambda kv: kv[1], reverse = True)
# kv[0] => [(1, 3), (2, 2), (3, 1)]
# kv[1] => [(3, 1), (2, 2), (1, 3)]
return [ x for x, _ in sorted_x[:k]]
(3) heap이용
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
freqs = collections.Counter(nums);
freqs_heap = []
for f in freqs:
heapq.heappush(freqs_heap, (-freqs[f], f))
topk = list();
for _ in range(k):
topk.append(heapq.heappop(freqs_heap)[1])
return topk
class Solution:
def numJewelsInStones(self, jewels: str, stones: str) -> int:
jewel = collections.Counter(jewels)
count = 0;
for stone in stones:
if stone in jewel:
count += 1;
return count
<출처>
1. https://namu.wiki/w/%ED%95%B4%EC%8B%9C?from=%ED%95%B4%EC%8B%9C%20%ED%95%A8%EC%88%98
2.
'Programming > 자료구조' 카테고리의 다른 글
| [자료구조] 정렬 (0) | 2022.04.17 |
|---|---|
| [자료구조] Queue & Stack (0) | 2022.04.02 |
| [자료구조/코테] Math (0) | 2022.03.01 |
| [자료구조/코테] 시간복잡도 및 알고리즘 정리 (0) | 2022.03.01 |
| [자료구조/코테] DFS/BFS (0) | 2022.03.01 |