
티스토리 뷰
0. Language Representation
- 인간의 언어를 다차원 벡터로 표현하여 컴퓨터가 이해할 수 있도록 하자!
- 언어를 어떻게 잘 표현해낼 수 있을까?
- 어떤식으로 표현해야지 좋을까?
- 어떻게 지식표현 체계로 바꿀 수 있을까?
1. One HOT - 희소표현(Sparse Representation)
- 과거 word prepresentation 방법은 원핫 인코딩(one-hot encoding) 방식을 주로 사용해왔음
- 원핫 인코딩을 통해서 원핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현
- 이러한 표현 항식은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다.
- 단어들 간의 관계성을 고려하여 표현하지 않음
2. 워드 임베딩(Word Embedding)
- 단어를 벡터로 표현하는 것
- 일반적으로 one hot encoding과 같은 sparse한 방식으로 표현된 단어를 더 낮은 차원의 dense한 실수 벡터 공간에 매핑하는 것
- 밀집표현(Dense Representation) - 워드 임베딩(Wrord Embedding)
- 희소 표현의 문제점을 해결하기 위해서 Dense한 표현형태로 변환하는 기법
- 더욱 더 효율적인 학습이 가능하게 하고 데이터의 차원을 축소해서 연산량을 감소시킴
- 텐서플로 라이브러리 임베딩 구현 tt.nn.embedding_lookup API 제공

워드 임베딩 방법론에는
1. Word2Vec ( CBOW, Skip-Gram 방식으로 나누어져 있음)
- 단어벡터보다 단어간의 유사도를 잘 측정한다.
- CBOW - 주변에 있는 단어를 가지고, 중간에 있는 단어를 예측
- Skip-Gram - 중간에 있는 단어로 주변 단어들을 예측하는 방법
- 사실 Word2Vec 모델은 딥러닝(Deep learning) 모델이 아니라 얕은 신경망(Shallow Neural Network) 모델
- Neural Network Language Model, NNLM 의 느린 학습속도와 정확도를 개선하여 탄생한 모델이 Word2Vec
2. Glove
3. FastText
2.1. Word2Vec
2.1.1 CBOW(Continuous Bag of Words)
- 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
- CBOW의 인공신경망을 도식하면 다음과 같음.
- 입력값으로 여러개의 단어를 사용하고, 학습을 해 하나의 단어와 비교
예문 : "The fat cat sat on the mat"
- Input layer의 입력으로서 앞, 뒤로 사용자가 정한 윈도우 크기 범위안에 있는 주변 단어들의 one-hot vector가 들어가게됨
- 투사층의 크기가 M -> 임베딩하고 난 벡터의 차원

2.1.2 Skip-Gram
- 중간에 있는 단어로 주변 단어들을 예측하는 방법
- 중심 단어에 대해서 주변 단어를 예측하기 때문에 투사층에서 벡터들의 평균을 구하는 과정은 없음
- Skip-Gram이 CBOW 보다 성능이 좋음

3. 글로브(GloVe)
- 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적
- LSA(Latent Semantic Analysis)? 각 문서에서의 단어의 빈도수를 카운트 한 행이라는 전체적인 통계 정보를 입력으로 받아 차원 축소하여 의미 끌어내기
- Word2Vec? 실제값과 예측값에 대한 오차를 손실함수를 통해 줄여나가며 학습하는 예측 기반의 방법론
4. FastText
- 2016년 FaceBook reserach에서 제안한 word representation 생성 및 text classification 방법
- 단어를 구성하는 n-gram vector들의 합으로 단어 vector 생성
- 단어 내부 정보를 활용하자
- C++로 구성되어 있기 때문에 속도도 굉장히 빠르다.
<출처>
2.텐서플로와 머신러닝으로 시작하는 자연어처리 출처
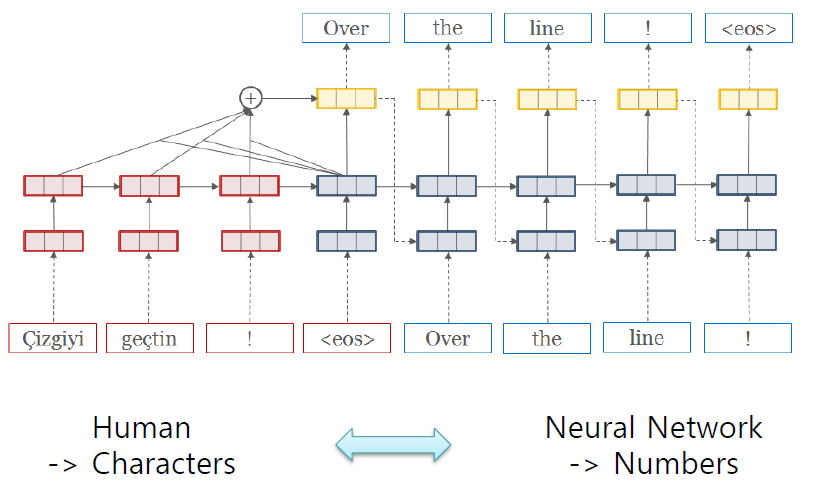
3. 본 내용은 T academy의 기계번역을 보고 정리한 내용입니다.
'인공지능 > 자연어처리' 카테고리의 다른 글
| 자연어처리 - 전처리(영어) (1) | 2020.01.15 |
|---|---|
| 자연어처리 - 기계번역 (1) | 2019.12.30 |
| 자연어처리 - Language Representation (2) (0) | 2019.12.30 |
| 자연어처리 - 기초 (0) | 2019.12.30 |
| 자연어처리 - WSL 환경에서 시작하기 (1) | 2019.12.25 |
댓글