
티스토리 뷰
0. 텍스트 유사도(Text Similarity)
- 텍스트가 얼마나 유사한지를 표현하는 방식 중 하나
- 딥러닝에서는? 단어, 형태소, 유사도의 종류에 상관없이 딥러닝을 기반으로 텍스트를 벡터화 한 후 벡터화된 각 문장간의 유사도 측정
1. 자카드 유사도(Jaccard Similarity)
- 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식 중 하나
- 유사도를 측정하는 방법은 두 집합의 교집합인 공통된 단어의 개수를 두집합의 합집합
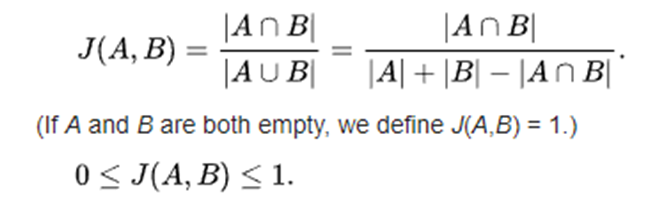
2. 코사인 유사도
- 두개의 벡터 값에서 코사인 각도를 구하는 방법
- 코사인 유사도 값은 -1과 1 사이의 값을 가지고 1에 가까울수록 유사
- 다른 유사도 접근법에 비해 성능이 좋다. -> 두 벡터간의 각도를 구하는 것이기 때문에 방향성의 개념이 더해진다.
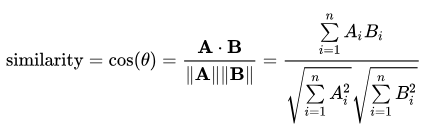
3. 유클리언 유사도
- 가장 기본적인 거리를 측정하는 유사도 공식
- 유클리언 유사도는 단순히 두 점 사이의 거리를 뜻하기 때문에 값에 제한이 없음. 크기는 계속해서 커질 수 있음
- 유클리디언거리 = L2 거리
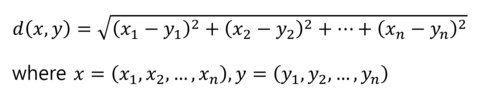
4. 맨하탄 유사도 (Manhattan distance, Taxicab geometry)
- 맨하탄 거리를 통해 유사도를 측정하는 방법
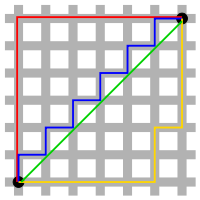
- 맨하탄 거리란? 사각형 격자로 이뤄진 지도에서 출발점에서 도착점까지를 가로지르지 않고 갈 수 있는 최단거리를 구하는 공식
- 맨하탄 = L1 거리
- 아래 그림 기준 유클리디언 거리는 검은색 선을 의미한다. 하지만 검은색 선은 도로와 도로 사이에 아무런 장애물이 없다고 가정한 것이기 때문에 현실성이 없음
- 가장 적합한 맨하탄 거리는 빨간색을 의미하며, 도로를 감안해서 가장 짧은 거리의 길이
<출처>
1. 텐서플로와 머신러닝으로 시작하는 자연어처리
2. https://towardsdatascience.com/overview-of-text-similarity-metrics-3397c4601f50
Overview of Text Similarity Metrics in Python
While working on natural language models for search engines, I have frequently asked questions “How similar are these two words?”, “How…
towardsdatascience.com
'인공지능 > 자연어처리' 카테고리의 다른 글
| 자연어처리 - WSL 환경에서 시작하기 (1) | 2019.12.25 |
|---|---|
| 자연어처리 - 코랩(Colab) 시작하기 (0) | 2019.12.25 |
| 자연어처리 - 임베딩 파인튜닝 (1) | 2019.12.25 |
| 자연어처리 - 임베딩 (0) | 2019.10.26 |
| 자연어처리 - 특징 추출(CountVectorizer, TfidVectorizer, HashingVectorizer) (0) | 2019.10.26 |
댓글