
티스토리 뷰
0. pandas로 csv 파일 읽기
|
1
2
3
4
5
|
train = pd.read_csv('./train/train.csv')
test = pd.read_csv('./test/test.csv')
print(train.head(5))
print(test.head(5))
|
cs |
1.1 train , test shape 확인하기
|
1
2
3
|
print('We have {} training rows and {} test rows.'.format(train.shape[0], test.shape[0]))
print('We have {} training columns and {} test columns.'.format(train.shape[1], test.shape[1]))
train.head(2)
|
cs |
1.2 train.head()
- 정보보기

|
1
2
|
print(train.describe())
print(train.info())
|
cs |
2. train.describe()
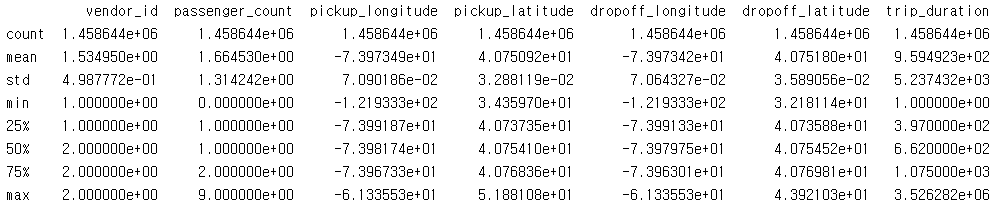
+ train.describe().T
>> transform 한 값을 얻을 수 있음
3. train.info()

4. 평균구하기
|
1
2
|
m = np.mean(train['column1'])
s = np.std(train['column1'])
|
cs |
5. 숫자 기준으로 정리하기
- 70보다 작은 train값으로 변경
|
1
2
|
train = train[train['column1'] <= 70]
|
cs |
6. 새로운 열을 추가해서 만들기
|
1
|
train.loc[:,'new column'] = train['old column'].dt.date
|
cs |
- old column 열을 사용해서 new column 라는 열을 새로 만듬
- 이떄 dt.date라는 건 날짜로만 바꿔주는것
7. 빈출 숫자를 groupby로 이용해서 나타내 주는 것
|
1
|
train.groupby('passenger_count').size()
|
cs |
- passenger_count라는 것을 통해 빈출 숫자를 알아보는것
- pandas 기준
8. pandas에 있는 값 알아보기
- column_name 에 내가 원하는 column_name넣고 value 값 찍어보기
|
1
2
|
what_type = train.column_name.values[:500000]
type(what_type) #numpy.ndarray
|
cs |
9. pandas get_dummies
- 숫자도 범주형으로 바꾸는것
- Pandas str.get_dummies() is used to separate each string in the caller series at the passed separator. A data frame is returned with all the possible values after splitting every string. If the text value in original data frame at same index contains the string (Column name/ Splited values) then the value at that position is 1 otherwise, 0.
- 출처 : 사이트 geeksforgeeks
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# importing pandas
import pandas as pd
# making data frame from csv at url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/employees.csv")
# making dataframe using get_dummies()
dummies = data["Team"].str.get_dummies(" ")
# display
dummies.head(10)
|
cs |
10. 크기 알아보기
-> vendor_train.shape
11. 원하지 않는 column name 삭제하기
- drip -> 삭제
- axis = 1 -> 방향
|
1
|
train.drop(['column_name'],axis = 1)
|
cs |
12. 행의 정보 알아내는 방법 (pandas apply)
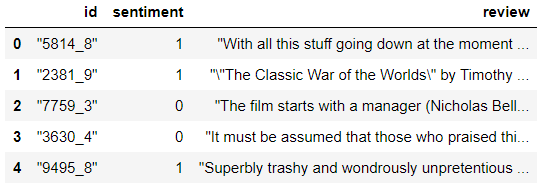
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#review 1행,2행.. 행마다의 길이
train_length = train_data['review'].apply(len)
#띄어쓰기로 구분된 단어의 단어의 갯수
train_data['review'].apply(lambda x : len(x.split(' ')))
#question mark, 대문자가 있는 질문... 등
qmarks = np.mean(train_data['review'].apply(lambda x : '?' in x))
fullstop = np.mean(train_data['review'].apply(lambda x : '.' in x))
capital_first = np.mean(train_data['review'].apply(lambda x : x[0].isupper()))
capitals = np.mean(train_data['review'].apply(lambda x : max([y.isupper() for y in x])))
numbers = np.mean(train_data['review'].apply(lambda x : max([y.isdigit() for y in x])))
|
cs |
'인공지능 > 캐글' 카테고리의 다른 글
| pytorch에 Albumentations란? (0) | 2020.06.28 |
|---|---|
| Evaluation 종류 (추가예정) (0) | 2020.06.10 |
| 벡터의 내적과 외적 (0) | 2020.04.21 |
| Kaggle Project - Pima Indians Diabetes Database (0) | 2019.10.17 |
| Kaggle Project - Predict Future Sales (0) | 2019.10.06 |
댓글