
티스토리 뷰
1. Stochastic Gradient Descent
1.1 Batch Gradient Descent
1.2 Stochastic Gradient Descent
1.3 Mini-batch Gradient Descent
2. Better Gradient Descent Methods
2.1 Momentum
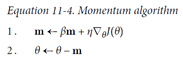
- 모멘텀 최적화는 이전 그래디언트가 얼마였는지를 상당히 중요하게 생각함.
- 매 반복에서 현재 그래디언트를 (학습률 η 를 곱한 후 ) 모멘텀벡터 m (momentum vector)에 더하고 이 값을 빼는 방식으로 가중치를 갱신한다.
- 그래디언트를 속도가 아니라 가속도로 사용한다.
- 일종의 마찰 저항을 표현하고 모멘텀이 너무 커지는 것을 막기 위해 알고리즘에 모멘텀(momentum)이라는 새로운 하이퍼 파라미터 β 가 등장.
- β : 높은 마찰 저항시 0, 마찰 저항 없음 1, 일반적인 모멘텀 값은 0.9
2.2 Nesterov Accelerated Gradient(NAG) - 네스테로프 가속 경사

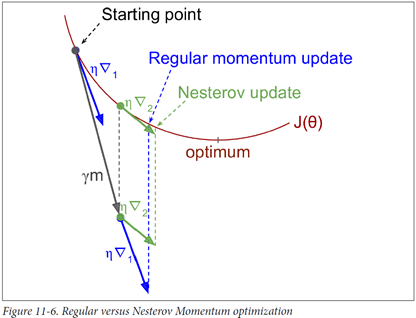
1983년 유리 네스토로프가 제안한 모멘텀 최적화의 한 변종
기본 아이디어? 현재 위치가 아니라 모멘텀의 방향으로 조금 앞서서 비용 함수의 그래디그래디 계산하는 것.
2.3 Adagrad


- AdaGrad 알고리즘? 가장 가파른 차원을 따라 그래디언트 벡터의 스케일을 감소시켜 이 문제를 해결
- 이 알고리즘은 학습률 η 을 감소시키지만 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감소 -> 적응적 학습률(adaptive learning rate) => 전역 최적범 방향으로 더 곧장 가도록 갱신되는데 도움이 된다.
- 간단한 2차 방정식 문제에 대해서는 잘 작동하지만 신경망을 훈련시킬 때 너무 일찍 멈춰버리는 경향이 있다. -> 학습률이 너무 감소되어 전역 최적점에 도착하기 전에 알고리즘이 완전히 멈춘다.
- 텐서플로우에 adaGradOptimizer가 있지만 심층 신경망에는 사용하지 말아야 한다.(하지만 간단한 선형 회귀 같은 간단한 작업에는 효과적)
2.4 RMSprop

2.5 Adam

- Adam 최적화? 적응적 모멘트 추정(adaptive moment estimation)?
- 모멘텀 최적화와 RMSProp의 아이디어를 합친 것
- 모멘텀 최적화처럼 지난 그래디언트의 지수 감소 평균(exponential decaying average)을 따르고 RMSProp 처럼 지난 그래디언트 제곱 지수 감소된 평균을 따른다.
<출처>
1. 핸즈온 머신러닝
'인공지능 > 딥러닝' 카테고리의 다른 글
| pytorch mode 기본 구현하기 (0) | 2020.07.28 |
|---|---|
| 딥러닝(Deep Learning) - 오버피팅(Overfitting)과 언더피팅(Underfitting) (0) | 2020.06.11 |
| 딥러닝(Deep Learning) - CNN 최신 분류 아키텍쳐(AlexNet,VGG-16,Inception,ResNet,MobileNet) (0) | 2020.06.11 |
| [Object Detection] 객체 검출 알고리즘 - 작성중 (2) | 2020.06.10 |
| 딥러닝 - EfficientNEt (0) | 2020.01.16 |
댓글