
티스토리 뷰
0. Generative model
중요한것
1. PixcelRNN/CNN
2. Variational Autoencoder
3. GAN
Generative model?
- 주어진 트레이닝 데이터의 특징을 학습하여 트레이닝 데이터와 유사한 새로운 데이터를 생성하는데 목적이 있음
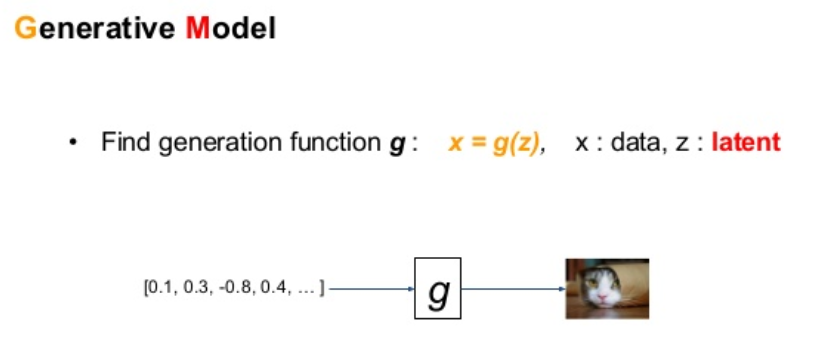
- 입력변수(latent variable) z로부터 결과물(image)를 만들어내는 모델
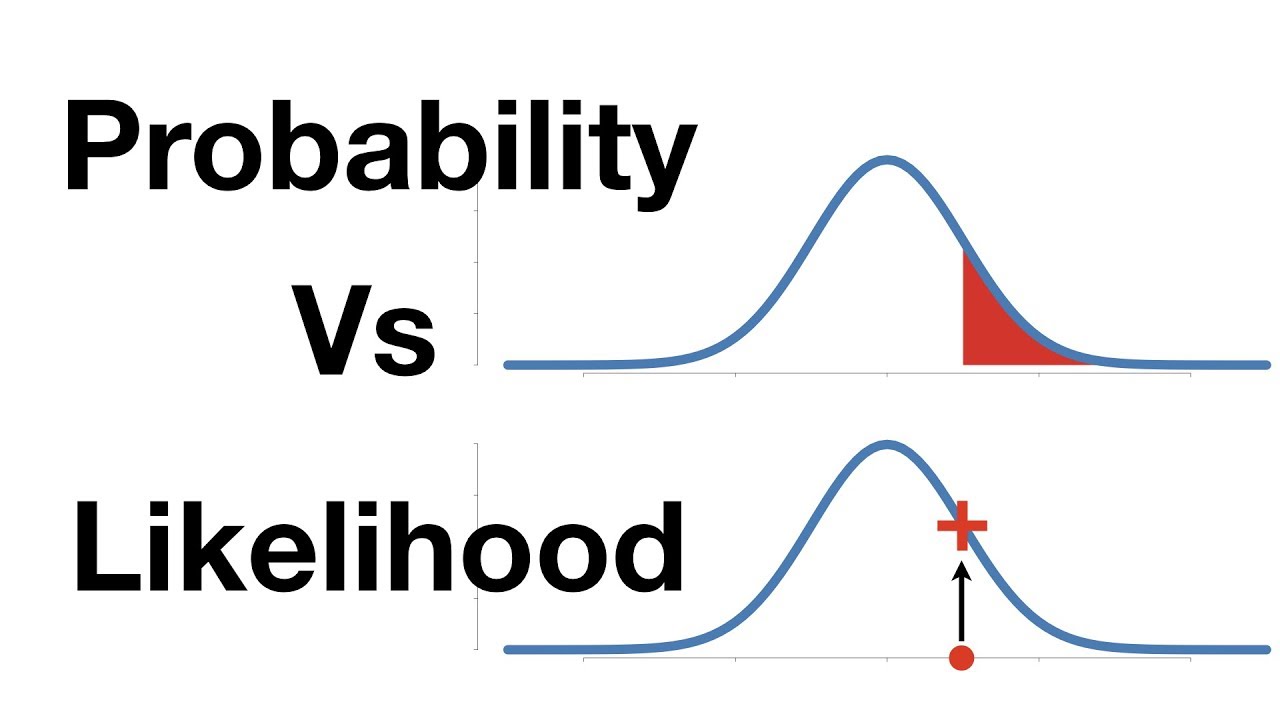
- maximum likelihood(ML)를 바탕으로 학습을 하는 것
- Maximum Likelihood method? 가장 큰 우도(likelihood)을 찾는 문제, 주어진 추정 계수로 관측값이 발생할 확률
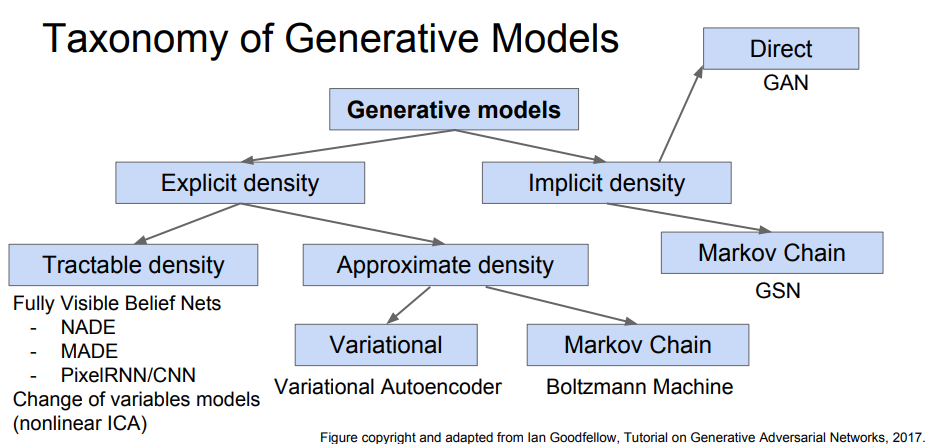
- Implicit density - model에 대해 틀을 명확히 정의하는 대신 확률 분포를 알기 위해 sample을 뽑는 방법
- >>Markov Chain : 무작위로 많이 샘플을 뽑아서 분포를 유추해보는 것
- Explicit density - model을 명확히 정의하여 이를 최대화하는 전략
- >> 여기서 계산이 가능한지(Tractable density) , 혹은 불가능한지(intractable)한지 두갈래로 나뉨
1.1. Latent Variables(잠재변수)
- 숨겨진 변수로써 데이터에 직접적으로 나타나지 않지만 현재 데이터 분포를 만드는데 영향을 끼치는 변수
- 어떤 데이터의 잠재 변수를 알아내면 잠재 변수를 이용해서 해당 데이터와 유사한 데이터를 생성해낼 수 있음
- Latent Variable = 데이터의 특징 ex) 동물의 모습 (동물, 고양이 = 1,2) 일종의 Latent Variable
1. Autoencoders - Background
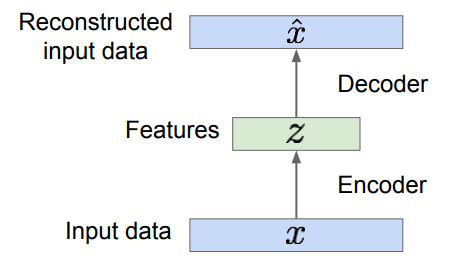
오토인코더란?
- 대표적인 비지도학습(Unsupervised Learning)을 위한 인공 신경망 구조 중 하나
- 어떤 값을 예측하거나 분류하는 것이 목적인 지도학습(Supervised Learning)과는 다르게 데이터의 숨겨진 구조를 발견하는것이 목표인 학습방법
- Autoencoders can reconstruct data, and can learn features to initialize a supervised model
<구조>
- Encoder = Originally: Linear + nonlinearity (sigmoid) Later: Deep, fully-connected Later: ReLU CNN
- Decoder = Originally: Linear + nonlinearity (sigmoid) Later: Deep, fully-connected Later: ReLU CNN(upconv)
2. Variational Autoencoder
- GAN 이전에 generative model에 대표적인 문제
- generative model 중의 하나로, 확률분포 p(x) 를 학습함으로써, 학습한 확률 분포로부터 데이터를 생성하는게 목적
- 실제 알고 싶은것? p(x) 실제 데이터 분포
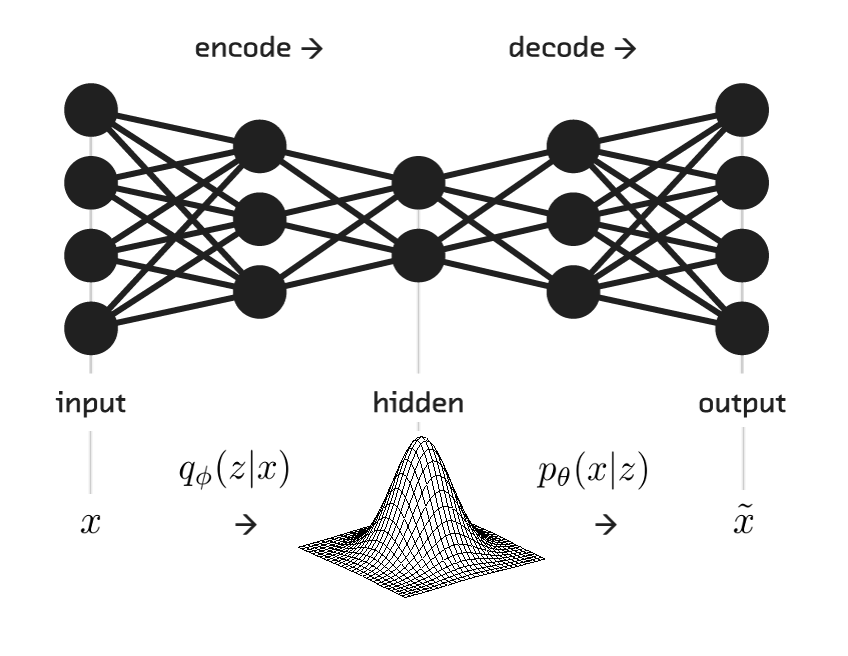
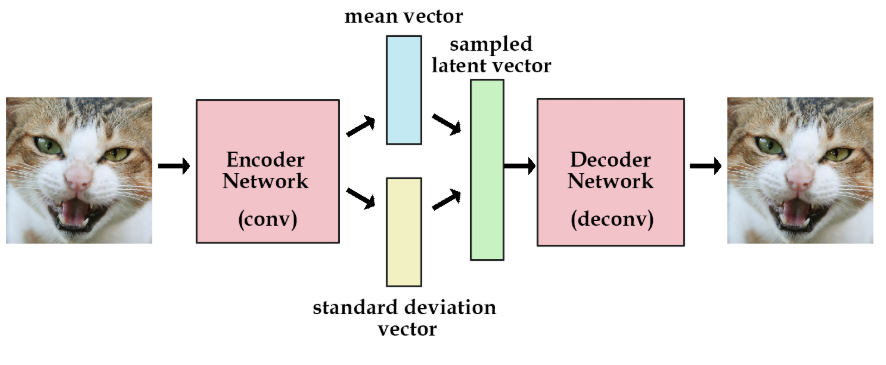
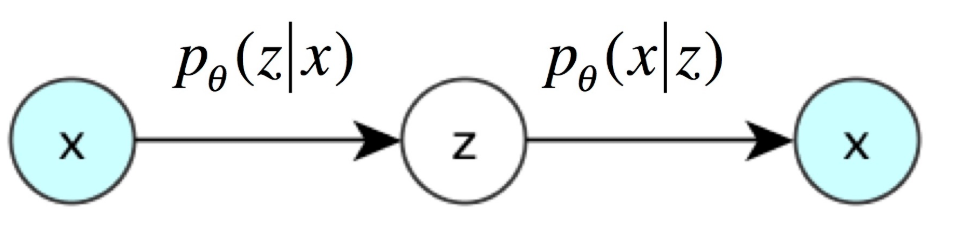
- VAE의 encoder은 주어진 x로부터 z를 얻을 확률 p(z|x)
- VAE의 decoder은 z로부터 x를 얻을 확률 p(x|z)
2.1 Encoder
- 데이터가 주어졌을 때 Decoder가 원래의 데이터로 잘 복원하루수 있는 z를 샘플링 할 수 있는 이상적인 확률 분포 p(z|x)를 찾는 것
- VAE 방법론에서는 Variational Inference 방법론 사용
Variational inference
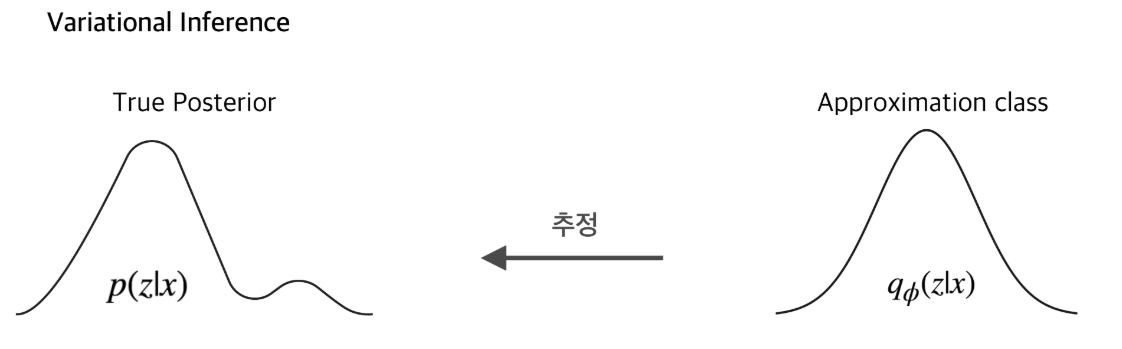
- 우리가 이상적인 확률분포를 모르지만, 이를 추정하기 위해서 다루기 쉬운 분포(approximation class, 대표적으로 Gaussian distribution)를 가정하고 이 확률분포의 모수를 바꿔가며, 이상적인 확률분포에 근사하게 만들어 그 확률분포를 대신 사용하는 것
- Intractible to compute P(x|z) for every z !
- P(z|x)를 근사할 수 있는 q(z|x) form을 근사시킴
# Reparameterization Trick
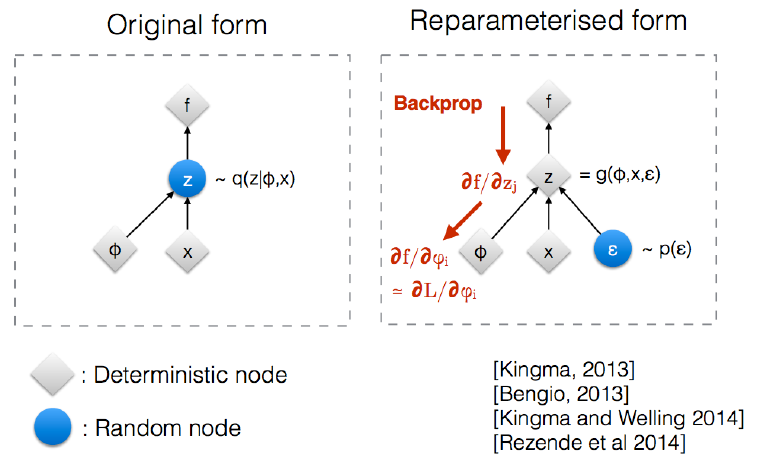
- Encoder가 출력하는 것은 q(z|x)의 모수
- q(z|x)를 정규분호로 가정했기 때문에 이러한 확률 분포로부터 샘플링을 함
- 그냥 샘플링시 chain이 끊기기 때문에 미분(Backpropagation)이 불가능하기 때문에 Reparameterization trick을 사용
- 가우시안 정규 분포의 샘플을 추출하고 싶을 때, 아래의 식과 같이 샘플링을 하는것
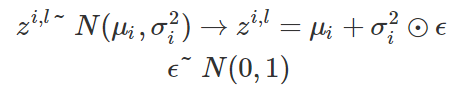
- 이렇게 샘플을 추출하더라도 원래의 확률적 특성을 보존
- z는 확률 분포의 모수인 분산과 평균이 더해진 형태이므로 미분(Backpropagation) 가능
2.2 Decoder
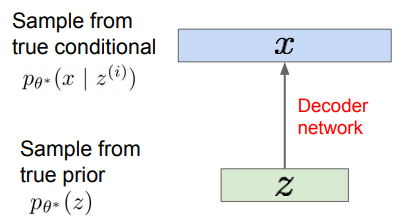
- 추출한 샘플을 입력으로 받아, 다시 원본으로 재구축하는 역할
2.3 정리

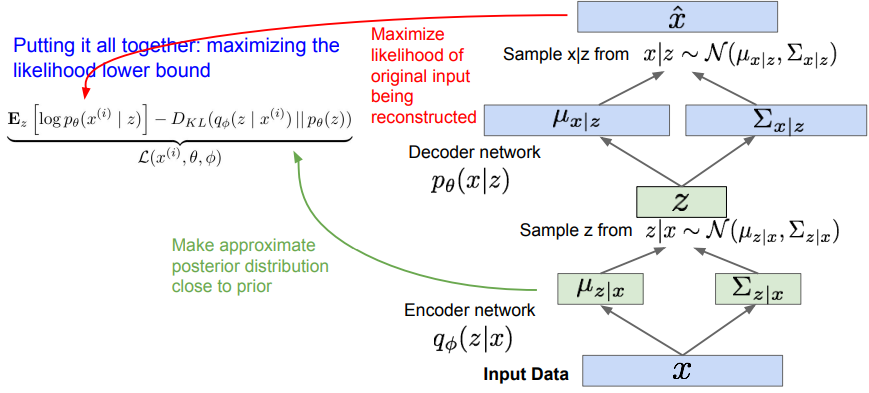
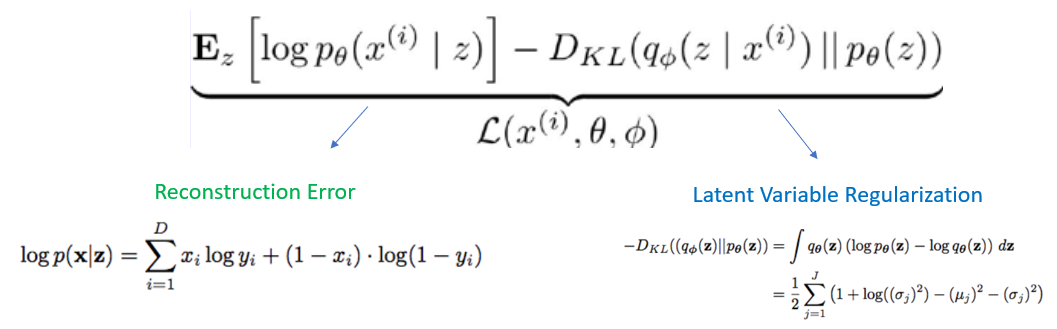
3. VAE 장단점
- 장점
- Log-likelihood통해 model quality 평가가능
- 생성 모델에 대한 원칙적 접근
- q (z | x)의 추론 가능, 다른 작업에 유용한 기능 표현 가능
- 단점
- 결과물의 질이 떨어짐
- 가능성의 하한을 최대화함
- PixelRNN / PixelCNN만큼 좋지는 않지만 쓸만함
- 최신식 (GAN)에 비해 샘플이 흐릿하고 품질이 떨어짐
<출처>
1. 재이미강님 깃허브
2. https://towardsdatascience.com/generating-images-with-autoencoders-77fd3a8dd368.
Comprehensive Introduction to Autoencoders
In the following weeks, I will post a series of tutorials giving comprehensive introductions into unsupervised and self-supervised learning using neural networks for the purpose of image generation…
towardsdatascience.com
3. https://datascienceschool.net/view-notebook/c5248de280a64ae2a96c1d4e690fdf79/
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep Learning) - RNN,LSTM, GRU (0) | 2019.10.18 |
|---|---|
| 딥러닝(Deep Learning) - GAN (0) | 2019.10.18 |
| 딥러닝(Deep Learning) - CNN 기본개념 (0) | 2019.10.18 |
| [1] tensorflow - 헷갈리는것 shape 정리 (0) | 2019.09.11 |
| [1] Machine learning basic (0) | 2019.09.05 |