
티스토리 뷰
1. Generative adversarial network(GAN)

- 비지도학습 GAN은 원 데이터가 가지고 있는 확률 분포를 추정하도록 하고, 인공신경망이 그 분포를 만들어낼 수 있도록 한다는 점에서 단순한 군집화 기반의 비지도 학습과 차이가 있음
- GAN에서 다루고자 하는 모든 데이터? 확률 분포를 가지고 있는 랜덤변수(Random Variable)
- GAN과 같이 비지도학습이 가능한 머신러닝 알고리즘으로 데이터에 대한 확률분포를 모델링할 수 있게 되면, 원 데이터와 확률분포를 정확히 공유하는 무한히 많은 새로운 데이터를 새로 생성할 수 있음
2. Generator(생성자)와 Discriminator(구분자)

Generator(생성자) : Discriminator을 속이기 위한 이미지 생성 학습
Discriminator(구분자) : 주어진 이미지가 진짜 이미지인지 가짜 이미지인지 구분하도록 판별
3. GAN의 손실함수
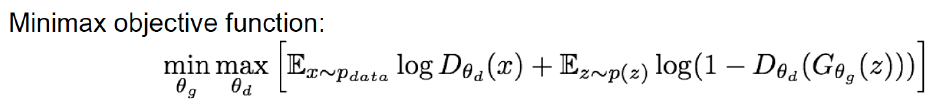
Discriminator D는 진짜 데이터 x를 입력받았을 경우 D(x)가 1로 생성자가 잠재 변수로부터 생성한 가짜 데이터 G(z)를 입력받았을 경우 D(G(z))를 0으로 예측하고 함
Generator는 생성한 가짜 데이터 G(z)를 구분자가 입력 받는 경우 (=D(G(z)) 구분자가 이를 1를 예측하도록 하는 것을 목표로 학습

1번 설명 - Discriminator - Gradient Ascent 최대화
- 최대값으로 파라미터를 업데이트 하는 것을 목표
- 구분자 입장에서 최상의 경우(진짜 이미지1, 가짜 이미지 0으로 출력하는 경우)
- 실제 데이터를 정확히 식별한다는 것? D(x) = 1,
- 가짜 데이터를 정확히 분류하는 것 D(G(z)) = 0
- 진짜 이미지를 입력받으면 1, 가짜 이미지를 입력 받으면 0을 출력하는 것으로 목표 손실 함수로 구성
2번 설명 - Generator - Gradient Descent 최소화
- 위 식의 최소값으로 파라미터 업데이트
- 생성자 입장에서 최상의 경우(구분자가 생성자가 생성한 가짜 이미지를 1로 출력한 경우) D(G(z)) =1 , 이는 최ㄱ소값이 된다.
<핵심>
GAN을 학습시키기 위해서는 구분자와 생성자의 파라미터를 번갈아가면서 업데이트를 해주어야한다.
구분자의 파라미터를 업데이트할 때에는 생성자의 파라미터를 고정시키고, 생성자의 파라미터를 업데이트할 때는 구분자의 파라미터를 고정해주어야 한다.
4. DCGAN
안정적으로 GAN을 학습시킬 수 있는 Deep Generative Adversarial Networks(DCGAN) 구조를 제안

4. GAN Code - 출처 : [텐서플로] GAN - 골빈해커의 3분딥러닝 텐서플로맛 #13
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
mnist = input_data.read_data_sets("./mnist/data/", one_hot = True)
#hyper parameter
total_epoch = 100
learning_rate = 0.0002
batch_size = 100
n_hidden = 256
n_input = 28*28
n_noise =128
#input of generator - enter random noise & put MNIST image
#n_noise는 generator의 input으로 사용할 노이즈 크기
#랜덤할 노이즈 입력 후 그 노이즈에서 MNIST 이미지를 무작위로 생성할 것
dir = "gan_samples"
if not os.path.isdir(dir):
os.mkdir(dir)
print("make directory ")
X = tf.placeholder(tf.float32, [None,n_input])
Z = tf.placeholder(tf.float32, [None,n_noise])
#생성기 신경망에 사용하는 변수들
with tf.name_scope("Generator_1") as scope:
G_W1 = tf.Variable(tf.random_normal([n_noise,n_hidden], stddev = 0.01))
G_b1 = tf.Variable(tf.zeros([n_hidden]))
with tf.name_scope("Generator_2") as scope:
G_W2 = tf.Variable(tf.random_normal([n_hidden,n_input], stddev = 0.01))
G_b2 = tf.Variable(tf.Variable(tf.zeros([n_input])))
#판별기 신경망에 사용하는 변수들
with tf.name_scope("Discriminator_1") as scope:
D_W1 = tf.Variable(tf.random_normal([n_input,n_hidden], stddev = 0.01))
D_b1 = tf.Variable(tf.zeros([n_hidden]))
# 판별기의 최종 결과값은 얼마나 진짜와 가깝냐를 판단하는 한 개의 스칼라값입니다.
with tf.name_scope("Discriminator_2") as scope:
D_W2 = tf.Variable(tf.random_normal([n_hidden,1], stddev = 0.01))
D_b2 = tf.Variable(tf.zeros([1]))
def generator(noise_z):
hidden = tf.nn.relu(tf.matmul(noise_z, G_W1)+G_b1)
output= tf.nn.sigmoid(tf.matmul(hidden,G_W2)+G_b2)
return output
#discriminator 신경망은 0~1 사이 스칼라 값을 출력
def discriminator(inputs):
hidden = tf.nn.relu(tf.matmul(inputs,D_W1)+D_b1)
output = tf.nn.sigmoid(tf.matmul(hidden,D_W2)+D_b2)
return output
#무작위 노이즈를 만들어주는 함수
def get_noise(batch_size, n_noise):
return np.random.normal(size = (batch_size,n_noise))
#generator 신경망은 무작위로 생성한 노이즈를 받아 실제 이미지와 같은 이미지를 출력
G = generator(Z)
D_fake = discriminator(G)
D_real = discriminator(X)
with tf.name_scope("cost") as scope:
loss_G = tf.reduce_mean(tf.log(D_fake))
loss_D = tf.reduce_mean(tf.log(D_real)+tf.log(1-D_fake))
with tf.name_scope("train") as scope:
G_var_list = [G_W1, G_b1, G_W2, G_b2]
D_var_list = [D_W1, D_b1, D_W2, D_b2]
train_G = tf.train.AdamOptimizer(learning_rate).minimize(-loss_G, var_list=G_var_list)
train_D = tf.train.AdamOptimizer(learning_rate).minimize(-loss_D, var_list=D_var_list)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
loss_val_G, loss_val_D = 0,0
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = get_noise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict = {X:batch_xs, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict= {Z: noise})
print('Epoch:', '%04d' %epoch, 'G loss : {:.2}'.format(loss_val_G), 'D loss : {:.2}'.format(loss_val_D))
if epoch == 0 or (epoch + 1) % 10 == 0:
sample_size = 10
noise = get_noise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Z: noise})
fig, ax = plt.subplots(1, sample_size, figsize=(sample_size, 1))
for i in range(sample_size):
ax[i].set_axis_off()
ax[i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('gan_samples/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('Complete Optimization!')
|
cs |
<출처>
1. http://jaejunyoo.blogspot.com/2017/02/deep-convolutional-gan-dcgan-1.html
초짜 대학원생의 입장에서 이해하는 Deep Convolutional Generative Adversarial Network (DCGAN) (1)
Deep Convolutional GAN (DCGAN)에 대한 쉬운 설명 및 소개 / Easy introduction to Deep Convolutional Generative Adversarial Network (DCGAN)
jaejunyoo.blogspot.com
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep Learning) - seq2seq, Attention Mechanism (0) | 2019.10.26 |
|---|---|
| 딥러닝(Deep Learning) - RNN,LSTM, GRU (0) | 2019.10.18 |
| 딥러닝(Deep Learning) - Variational Autoencoder (0) | 2019.10.18 |
| 딥러닝(Deep Learning) - CNN 기본개념 (0) | 2019.10.18 |
| [1] tensorflow - 헷갈리는것 shape 정리 (0) | 2019.09.11 |