
티스토리 뷰
0. 설명하기 전에
RNN, LSTM, GRU 지식정보 필요 [링크]
1. 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
- 번역기에서 대표적으로 사용하는 모델
- LSTM, GRU 등 RNN을 길고 깊게 쌓아서 복잡하고 방대한 시퀀스 데이터 처리
- seq2seq는 크게 두 개로 구성된 아키텍처로 구성 -> 인코더, 디코더
- seq2seq에서 사용되는 모든 단어들은 워드 임베딩을 통해 임베딩 벡터로서 표현된 임베딩 벡터
- (Sutskever, et al. 2014).
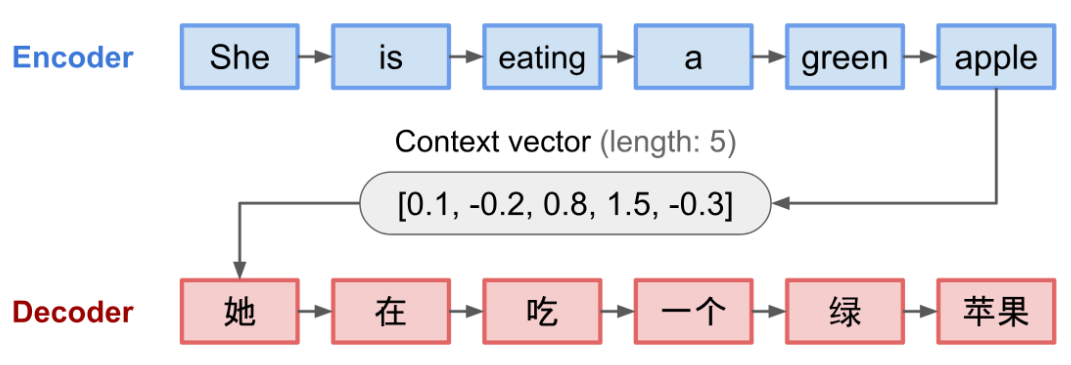
- 인코더(Encoder)란? 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해 하나의 벡터로 만듦
- 디코더(Decoder)란? 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냄
2. 어텐션 메커니즘 (Attention Mechanism)
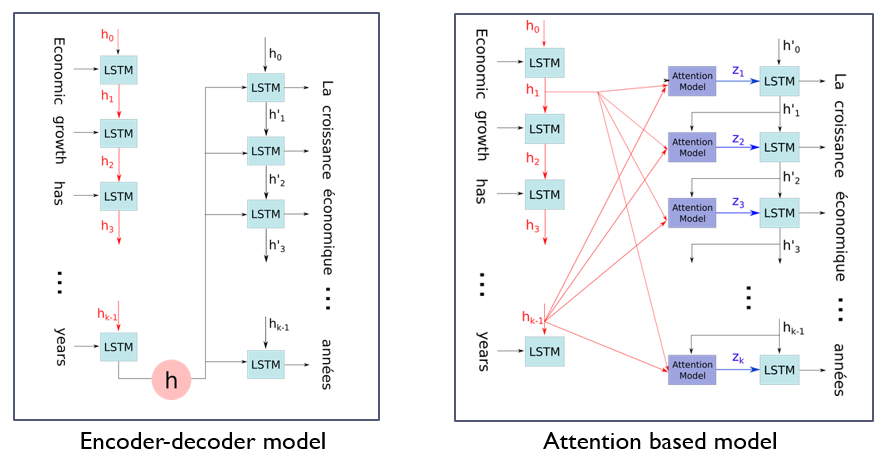
- seq2seq 모델은 Encoder에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, Decoder는 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냄
- 하지만 RNN 기반으로한 seq2seq 문제가 있음
- 고정된 벡터에 모든 정보 압축시 정보 손실 발생
- RNN 고질적인 문제 Vanishing Gradient 문제 발생
- Attention mechanism을 처음 소개한 논문 [링크]
2.1 Attention 아이디어
- Decoder에서 출력 단어를 예측 하는 매시점마다, Encoder에서의 전체 입력 문장을 다시 한번 참고
- 해당 시점에서 예측해야할 단어와 연관이 있는 입력단어 부분을 좀 더 집중(Attention)해서 보게됨
<출처>
2. https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
3.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 - EfficientNEt (1) | 2020.01.16 |
|---|---|
| 딥러닝(Deep Learning) - 활성화 함수 (0) | 2019.10.27 |
| 딥러닝(Deep Learning) - RNN,LSTM, GRU (0) | 2019.10.18 |
| 딥러닝(Deep Learning) - GAN (0) | 2019.10.18 |
| 딥러닝(Deep Learning) - Variational Autoencoder (0) | 2019.10.18 |
댓글