
1. 배열 Person[] public people uint[] memory result = new uint[](3) 2. 랜덤문자 생성 keccak256("aaaa") 3. 형변환 uint a = 5; uint b = 6; uint8 c = a*uint8(b) 3.1 uint 3.2 캐스팅 - uint32(uint256 변수) 4. 이벤트 5. Address 0x0cE446255506E92DF41614C46F1d6df9Cc969183 6. Mapping - 솔리디티 Storage에서 구조화된 데이터를 저장하는 또다른 방법, 오직 상태변수로만 선언 - 기본적으로 키 - 값(key - value) 저장소로 데이터를 저장하고 검색하는데 이용됨 - key는 실제로 저장되지 않고 키의 keccak256 해시값이..
 머신러닝 - 베이즈 통계학
머신러닝 - 베이즈 통계학
베이즈 정리 => “사전확률로부터 사후확률을 구할 수 있다” 베이즈 정리의 기본 베이즈 통계학은 조건부 확률관한 법칙인 베이즈 정리를 기본으로 둔다. 토머시스 베이즈, 알려지지 않은 사 전 분포에 관측값을 쌓아가면서 확실함을 더해가는 과정에 관심을 두고 연구 사건 A와 B가 있을 때, 사건 B가 일어난 것을 전제로 한 사건 A의 조건부 확률을 구하고 싶다고 하자. 그런데 지금 알고 있는 것은 사건 A가 일어난 것을 전제로 한 사건 B의 조건부 확률, A의 확률, B의 확률 뿐이다. 그럴 때, 원래 구하고자 했던 '사건 B가 일어난 것을 전제로 한 사건 A의 조건부 확률'은 다음과 같이 구할 수가 있다
 블록체인 합의알고리즘(Consensus algorithms)
블록체인 합의알고리즘(Consensus algorithms)
합의알고리즘 (Consensus algorithms) - 다수의 참여자들이 통일된 의사 결정을 하기위해 사용하는 알고리즘 - 권위있는 중앙이 존재하지 않기 때문에 통일된 의사결정필요! 들어가기 앞서서... 비잔틴 장군 문제 - 합의 시스템에서 악의적으로 정보를 변경시키는 행위에 대해 전체 시스템이 올바른 합의를 이룰 수 있도록 하는가? - 비잔틴 장군들 --> 어떠한 공격을 한다고 할때 일정 비율 이상 동시에 지역 공격해야지 성공 - 정보전달때 누군가가 악의적으로 정보 변경하지만 대다수의 장군들이 정확한 시간 날짜에 공격성공 - 결국 POW라는 증명 알고리즘을 통해 해결한것! 1. 작업증명(Proof of Work, PoW) - 목표값 이하의 해시를 찾는 과정을 무수히 반복함으로써 해당 작업에 참여했음을..
머신러닝을 하면서 hyperparameter에 대한 고민이 많았다. 단순히 노가다 성격이 아닌 어떻게 하는지 정리해보려고 한다. 핵심코드만 정리해둠 순서는 7가지나 자주 많이 쓰이는 GridSearch , BayesianOptimization ,Optuna 세 개만 정리해보려고 한다. 이건 개인적으로 정리하는 용도로 만들었기 때문에 만약에 전체 flow를 보고 싶다면 밑의 링크를 참고하면 된다. 전체코드는 여기서 보실 수 있음 순서 1. GridSearch 2. BayesianOptimization 3. Optuna 4. scikit-optimize 5. Hyperopt 6. Spearmint 7. benderopt 1. GridSearch - 기본적인 방법 1 2 3 4 5 6 7 8 9 10 11 1..
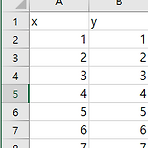 머신러닝 기본적인 LinearRegression Code
머신러닝 기본적인 LinearRegression Code
1. Data 만들기 - "data2.csv" 2. LinearRegression Code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pandas as pd import numpy as np df_data = pd.read_csv("data2.csv") x_data = df_data.drop(['y'],axis=1) y_data = df_data['y'] print(x_data.head(5)) print(y_data.head(5)) from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_score lin_reg = LinearRegre..
.. https://colab.research.google.com/github/rwightman/pytorch-image-models/blob/master/notebooks/EffResNetComparison.ipynb#scrollTo=xx-j8Z-z_EGo 불러오는 중입니다... https://github.com/Tony607/efficientnet_keras_transfer_learning/blob/master/Keras_efficientnet_transfer_learning.ipynb Tony607/efficientnet_keras_transfer_learning Transfer Learning with EfficientNet in Keras. Contribute to Tony607/efficien..
1. 클렌징 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import re def data_processing(text): text_re = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\`\'…》]', ' ', text) #Single character removal text_re = re.sub(r"\s+[a-zA-Z]\s+", ' ', text_re) # Removing multiple spaces text_re = re.sub(r'\s+', ' ', text_re) return text_re text = "DF+#$%^ $^&@$%} a " data_processing(text) """ 'DF } ' ..
 [ML Algorithm] 군집화(clustering)
[ML Algorithm] 군집화(clustering)
1. 군집화(clustering)이란? 주어진 데이터들의 특성을 고려해 데이터 집단(클러스터)을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법이다. 클러스터란 비슷한 특성을 가진 데이터들의 집단이다. 반대로 데이터의 특성이 다르면 다른 클러스터에 속해야 한다. (by 위키백과) 비지도학습종류 2가지 1. 데이터 클러스터링 2. 특성 변수 관계 탐색 -> 데이터 클러스터링? 여러번의 반복을 통해 데이터의 최적 분할을 진행하는 방법 -> 특성 변수 관계 탐색? 각종 연관성 분석 방법을 통해 변수 사이의 관계를 찾는것 2. 군집화 알고리즘 (1) K 평균 군집 중심점(centroid)라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화기법..
 자연어처리 - 기계번역
자연어처리 - 기계번역
0. 자연어처리? - 프로그래밍언어처럼 기계가 이해하는 언어가 아닌 한국어, 영어처럼 사람이 사용하는 언어를 기계가 분석하고 이해해서 사람과 커뮤니케이션 할 수 있도록 해주는 연구분야 1. 기계번역이란? - 자연어처리의 하나의 번역 - NLU + NLG 1.1 규칙기반 기계번역 1.2 통계기반 기계번역(SMT, Statistical Machine Translation) - 두 언어의 parallel corpus에서 co-occurance 기반의 통계 정보를 바탕으로 번역을 수행 - 지금 사용 X 1.3 인공신경망 기반 기계번역 (Neural Machine Translation) --> chapter 2 2. 인공신경망 기반 기계번역 (Neural Machine Translation) 2.1 구조 Enco..
 자연어처리 - Language Representation (1)
자연어처리 - Language Representation (1)
0. Language Representation 인간의 언어를 다차원 벡터로 표현하여 컴퓨터가 이해할 수 있도록 하자! 언어를 어떻게 잘 표현해낼 수 있을까? 어떤식으로 표현해야지 좋을까? 어떻게 지식표현 체계로 바꿀 수 있을까? 1. One HOT - 희소표현(Sparse Representation) 과거 word prepresentation 방법은 원핫 인코딩(one-hot encoding) 방식을 주로 사용해왔음 원핫 인코딩을 통해서 원핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현 이러한 표현 항식은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다. 단어들 간의 관계성을 고려하여 표현하지 않음 2. 워드 임베딩(Word Embedding) 단어를 ..